
Composition-based Multi-Relational Graph Convolutional Networks
Updated:
[paper review] CompGCN, ICLR 2020
Introduction
대부분의 Graph Convolutional Networks (GCNs) 는 simple, undirectred graph 에 대해서 연구가 이루어졌습니다. 더 일반적인 형태의 그래프는 edge 에 feature 와 direction 이 존재하는 multi-relational graph 이며, 예로 knowledge graph 가 있습니다. GCN 을 통해 multi-relational graph 를 분석하는 기존의 방법은 node representation 만을 학습할 수 있고, over-parametrization 의 문제가 있습니다. 특히 node 뿐만 아니라 node 사이 relation 에 대한 학습이 필요한 link prediction 의 경우 GCN 을 직접 사용하는데 어려움이 있습니다. 논문에서는 이런 문제점을 해결하기 위해 GCN 을 통해 node 의 representation 뿐만 아니라, relation 의 representation 을 같이 학습하는 CompGCN 모델을 제시합니다.
Background
Knowledge Graph
Knowledge graph 는 multi-relational graph 의 한 종류로 Freebase, WordNet 과 같은 knowledge base 를 그래프로 나타낸 것입니다. Entity 들을 node 로, entity 들 사이의 relation 을 edge 로 표현합니다. Node 들의 집합 \(\mathcal{V}\) 와 relation 들의 집합 \(\mathcal{R}\) 에 대해, edge 는 node \(u,v\in\mathcal{V}\)사이의 relation \(r\in\mathcal{R}\) 로 이루어진 triplet \((u,r,v)\) 로 정의됩니다. 이러한 edge 들의 집합으로 knowledge graph \(\mathcal{G} = \{(u,r,v)\} \subset \mathcal{V}\times\mathcal{R}\times\mathcal{V}\) 를 정의합니다.
Knowledge graph 는 수많은 triplet 들로 이루어져 있고, 많은 수의 triplet 들이 incomplete 합니다. 이를테면, 주어진 두 entity \(u\) 와 \(v\) 사이의 relation 이 알려지지 않은 triplet \((u,?,v)\), 혹은 node \(u\) 와 연결된 relation \(r\) 이 주어졌지만 tail entity 를 모르는 triplet \((u,r,?)\) 과 같은 케이스가 있습니다. 이런 imcomplete 한 triplet 을 완성하기 위해서는 link prediction 이 필요합니다. Link prediction 은 각 entity 와 relation 들에 대한 low-dimensional representation 을 찾고, 올바른 triplet 에 더 높은 score 를 부여하는 score function 을 통해 이루어집니다. 대표적인 모델로 TransE, DistMult, RotatE 등이 있습니다.
GCN on Multi-Relational Graphs
Simple undirected graph 에 대한 GCN 의 layer-wise propagation rule 은 다음과 같이 표현할 수 있습니다 [3].
\[H^{(k+1)} = f\left( \hat{A}H^{(k)}W^{(k)} \right) \tag{1}\]하지만 multi-relational graph 에도 \((1)\) 을 적용한다면, relation 에 대한 정보를 사용하지 않기 때문에 제대로된 representation 을 찾을 수 없습니다. 따라서 \((1)\) 의 \(W^{(k)}\) 대신 relation specific weight \(W^{(k)}_r\) 를 사용하여, 다음과 같이 새로운 propagation rule 을 정의할 수 있습니다.
\[H^{(k+1)} = f\left( \hat{A}H^{(k)}W^{(k)}_r \right) \tag{2}\]\((2)\) 를 사용할 경우 relation 의 수가 많아질수록 over-parametrization 이 쉽게 일어날 수 있다는 단점이 있습니다.
CompGCN Details
Directed-GCN [5] 과 같이 relation 이 단방향이 아닌 양방향으로 정의될 수 있도록, edge 와 relation 들의 집합 \(\mathcal{E}\) 과 \(\mathcal{R}\) 을 확장합니다. 기존의 edge \((u,r,v)\in\mathcal{E}\) 에 대해, relation \(r\) 의 방향을 뒤집은 inverse \(r^{-1}\) 를 이용한 inverse edge \((v,r^{-1},u)\) 와 self-loop \(\top\) 을 이용한 self edge \((u,\top,u)\) 을 추가해 새로운 edge 들의 집합 \(\mathcal{E}'\) 을 다음과 같이 정의합니다.
\[\mathcal{E}' = \mathcal{E}\,\cup\{(v,r^{-1},u):(u,r,v)\in\mathcal{E}\,\}\,\cup\{(u,\top,u):u\in V\}\]또한 기존의 relation \(r\in\mathcal{R}\) 에 대해 inverse relation \(r^{-1}\) 과 self-loop \(\top\) 을 추가한 새로운 relation 들의 집합 \(\mathcal{R}'\) 을 다음과 같이 정의합니다.
\[\mathcal{R}' = \mathcal{R}\,\cup\{r^{-1}:r\in\mathcal{R}\}\,\cup\{\top\}\]Self-loop \(\top\) 을 추가해주는 이유는 GCN [3] 에서와 같이 embedding 을 update 해줄 때 주변 node 들의 embedding 뿐만 아니라, 자가 자신의 embedding 에 대한 정보를 사용해주기 위해서입니다 [4, 5].
CompGCN 은 각 node \(u\in\mathcal{V}\) 에 대한 node embedding \(h_u\in\mathbb{R}^d\) 와 각 relation \(r\in\mathcal{R}'\) 에 대한 relation embedding \(h_r\in\mathbb{R}^d\) 을 학습합니다. 이 때 node embedding 과 relation embedding 의 차원이 같도록 설정해줍니다. 다음의 그림은 추가된 inverse relation 들과 node embedding, relation embedding 을 보여줍니다.
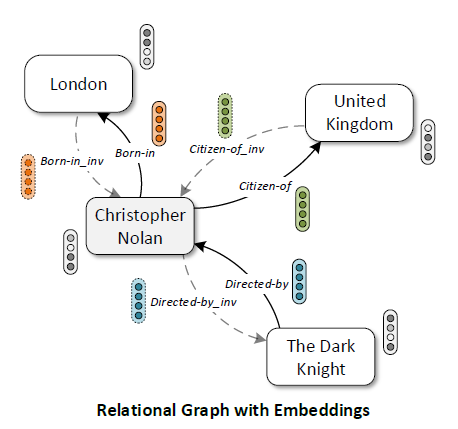
Composition Operation
GCN 에 relation embedding 을 적용하기 위해, entity-relation composition operation \(\phi:\mathbb{R}^d\times \mathbb{R}^d\rightarrow\mathbb{R}^d\) 을 사용합니다. 이는 entity 의 embedding \(h_v\) 와 relation 의 embedding \(h_r\) 을 통해 새로운 embedding \(\phi(h_v,h_r)\) 을 만들어주는 operation 입니다.
논문에서는 composition operation \(\phi\) 를 다음의 세 가지 non-parametrized operation 에 한정시킵니다.
- subtraction : \(\phi(h_v,h_r) = h_v - h_r\)
- multiplication : \(\phi(h_v,h_r) = h_v\ast h_r\)
- circular-correlation : \(\phi(h_v,h_r) = h_v\star h_r\)
각각의 operation 들은 TransE, DistMult, HolE 모델에서 영감을 받았다고 설명하지만, 실험 결과를 보면 operation 들에 특별한 의미가 있는 것 같지는 않습니다.
Node Embedding Update
\((2)\) 를 통한 node embedding 의 update 는 다음과 같이 정리할 수 있습니다.
\[h_u \leftarrow f\left( \sum_{(u,r,v)\in\mathcal{E}'}W_rh_v \right) \tag{3}\]\((3)\) 은 \(u\) 를 head entity 로 가지는 모든 edge \((u,r,v)\) 들에 대해, relation \(r\) 과 tail entity \(v\) 의 정보를 통해 \(u\) 의 새로운 embedding 을 update 하는 과정으로 이해할 수 있습니다. 이 때 over-parametrization 의 문제점을 가지는 relation specific weight \(W_r\) 을 사용하지 않기 위해, composition operation \(\phi(h_v,h_r)\) 을 통해 relation 에 대한 정보를 담아냅니다.
Composition operation 을 사용한다면, 모든 node 들에 대해 공통적인 weight \(W\) 를 사용해 \((3)\) 을 다음과 같이 바꿀 수 있습니다.
\[h_u \leftarrow f\left( \sum_{(u,r,v)\in\mathcal{E}'}W\phi(h_v,h_r) \right) \tag{4}\]더 나아가 \(\mathcal{E}'\) 에서 기존의 edge 와 새로 추가된 inverse edge, self edge 들을 구분하기 위해, \((4)\) 의 \(W\) 대신 direction specific weight \(W_{\text{dir}(r)}\) [5] 를 사용하여 새로운 update rule 을 정의해줍니다.
\[h_u \leftarrow f\left( \sum_{(u,r,v)\in\mathcal{E}'}W_{\text{dir}(r)}\,\phi(h_v,h_r) \right) \tag{5}\]이 때 direction specific weight \(W_{\text{dir}(r)}\) 는 다음과 같이 구분할 수 있습니다.
\[W_{\text{dir}(r)} = \begin{cases} W_O, & r\in\mathcal{R} \\ W_I, & r\in\mathcal{R}_{inv} \\ W_S, & r=\top \end{cases}\]\((5)\) 의 과정은 다음의 그림을 통해 이해할 수 있습니다.
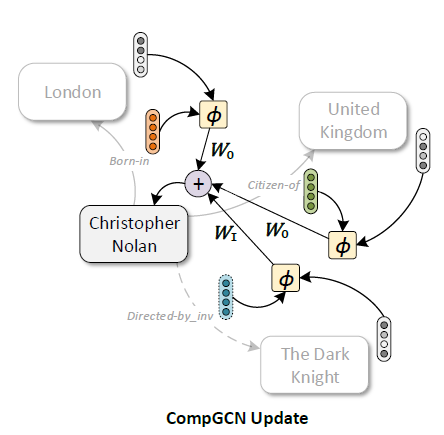
Relation Embedding Update
\((5)\) 를 통해 node embedding 을 update 한 후, 학습 가능한 행렬 \(W_{\text{rel}}\) 을 통해 다음과 같이 relation embedding 을 update 해줍니다.
\[h_r \leftarrow W_{\text{rel}}h_r \tag{6}\]Basis Formulation
또한 relation 의 수가 증가함에 따라 CompGCN 모델이 필요 이상으로 복잡해지는 것을 막기 위해, [4] 의 basis formulation 을 응용합니다. 각 relation 들의 initial representation 을 다음과 같이 학습 가능한 basis vector \(\{v_1,\cdots,v_{\mathcal{B}}\}\) 들의 linear combination 으로 표현합니다.
\[h_r^{(0)} = \sum^{\mathcal{B}}_{b=1} \alpha_{br}v_b \tag{7}\]여기서 \(\alpha_{br}\in\mathbb{R}\) 은 relation 과 basis vector 에 의존하는, 학습 가능한 scalar 입니다.
\((7)\) 을 통해 서로 다른 relation 들의 embedding 을 공통의 basis vector 들로 표현할 수 있습니다. 이를 weight sharing 관점에서 볼 때 수가 적은 (rare) relation 들과 수가 많은 (frequent) relation 들이 wegiht 을 공유하기 때문에, rare relation 들에 대해 overfitting 이 일어나는 것을 방지할 수 있습니다 [4]. CompGCN 은 Relational-GCN [4] 과 다르게, initial representation 만을 basis vector 로 표현하며 이후의 layer 에서는 basis 를 사용하지 않습니다.
Comparison With Other Models
\((5)\) 의 update rule 은 GCN [3], Relational-GCN [4], Directed-GCN [5], Weighted-GCN 모델들을 모두 일반화한 것입니다. 각각의 모델들은 다음의 표와 같이 \((5)\) 의 direction specific weight \(W_{\text{dir}(r)}\) 와 composition operation 을 특정해주어 나타낼 수 있습니다.
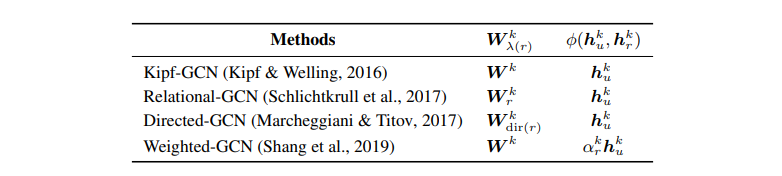
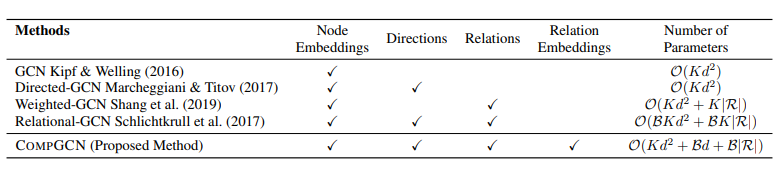
다음의 표는 각 모델들이 반영한 특징을 잘 정리해 놓았습니다.
Experiment & Results
논문에서는 CompGCN 모델을 link prediction, node classification, graph classification 세 가지 task 들에 대해 performance 를 측정합니다.
Link Prediction
Performance comparison
먼저 link prediction task 에 대해 5 가지 metric 으로 평가하여 모델들의 performance 를 비교합니다. FB15k-237 과 WN18RR 데이터셋에 대한 CompGCN 과 baseline 모델들의 성능을 측정한 결과는 다음의 표에 정리되어있습니다.
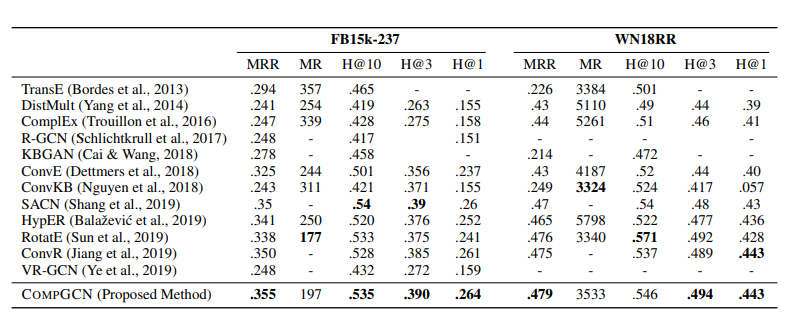
대부분의 metric 에서 CompGCN 의 성능이 가장 뛰어남을 확인할 수 있습니다. 2 가지 metric 에서 CompGCN 보다 뛰어난 성능을 보이는 RotatE [2] 모델은 entity 와 relation 을 복소수 영역에서 다루며, relation 을 rotation operation 으로 해석합니다. CompGCN 또한 complex domain 에서의 rotation operation 을 적용한다면, 더 우수한 성능을 낼 수 있지 않을까 기대해봅니다.
Relational-GCN 과 같은 기존의 모델 대신 CompGCN 을 사용하는 것이 얼마나 효과적인지에 대한 분석이 필요합니다. Score function \(X\) 와 entity embedding 을 위한 모델 \(M\) 그리고 CompGCN 의 경우 composition operator \(Y\) 의 다양한 조합 \(X+M(Y)\) 에 대해, FB15k-237 데이터셋에서 성능을 평가했습니다. 결과는 다음의 표에 정리되어 있습니다.
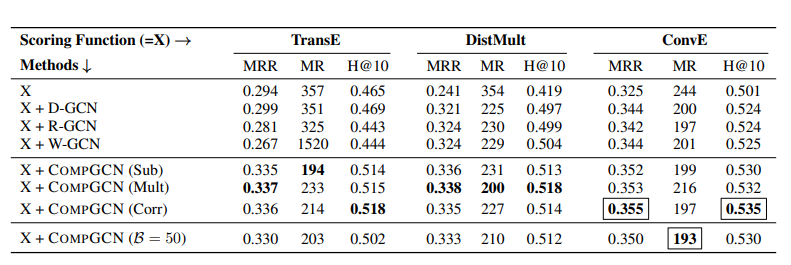
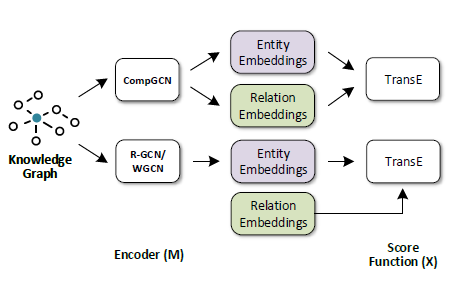
다양한 조합들 중, 모델 \(M\) 으로 CompGCN 을 사용했을 때 성능이 가장 좋음을 볼 수 있습니다. 대부분의 모델들은 TransE 의 score function 을 적용했을 때 성능이 눈에 띄게 떨어지지만, CompGCN 은 성능에 큰 차이가 나지 않습니다. CompGCN 의 performance 가 다른 모델들에 비해 뛰어난 이유는, node embedding 뿐만 아니라 relation embedding 을 같이 학습하기 때문이라고 추측할 수 있습니다. 다음의 그림에서 볼 수 있듯이 Relational-GCN 과 Weighted-GCN 은 entity embedding 만을 학습하지만, CompGCN 은 relation embedding 을 같이 학습하기 때문에 entity 와 relation 을 모두 고려해야하는 link prediciton task 에서 효과적입니다.
CompGCN 의 성능을 composition operation 에 따라 비교해보면, 사용한 score function 에 따라 달라지지만 대체적으로 circular-correlation 과 같이 복잡한 operation 을 사용한 경우 더 나은 performance 를 보입니다. 특히, 다양한 조합들 중 ConvE 의 score function, circular-correlation (Corr) 과 함께 CompGCN 을 사용했을 때의 성능이 가장 뛰어남을 확인할 수 있습니다.
Scalability
CompGCN 의 scalability 를 분석하기 위해, relation 의 수와 basis vector 의 수에 따른 CompGCN 의 performance 를 비교했습니다. FB15k-237 데이터셋에서 ConvE + CompGCN (Corr) 모델을 사용해 basis vector 의 수 \(\mathcal{B}\) 에 따른 성능을 측정하였고, 결과는 다음의 그래프와 같습니다.
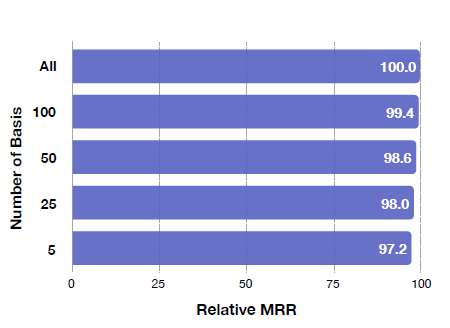
\(\mathcal{B}\) 가 커질수록 CompGCN 의 performance 가 좋아지며, \(\mathcal{B}=5\) 일 때에도 충분히 뛰어난 성능을 보입니다. \(\mathcal{B}\) 가 작을수록 parameter 의 수가 줄어들기 때문에, CompGCN 은 적은 parameter 로도 충분히 multi-relational graph 의 representatin 을 학습한다는 것을 알 수 있습니다.
Relational-GCN 과 자세히 비교하기 위해, \(\mathcal{B}=5\) 로 제한된 CompGCN 과 relation 의 수에 따른 성능을 측정하였습니다.
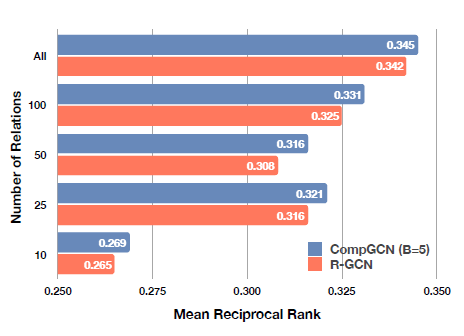
Relational-GCN 과 비교했을 때, \(\mathcal{B}=5\) 로 제한된 조건에서도 relation 의 수와 상관 없이 CompGCN 이 R-GCN 보다 더 좋은 성능을 보여줍니다.
Node Classification, Graph Classification
마지막으로 node classification 과 graph classification task 에서의 성능을 baseline 과 비교했습니다. Node classification 에 대해서는 MUTAG 과 AM 데이터셋에서의 정확도를, graph classification 에 대해서는 MUTAG 과 PTC 데이터셋에서의 정확도를 측정했습니다.
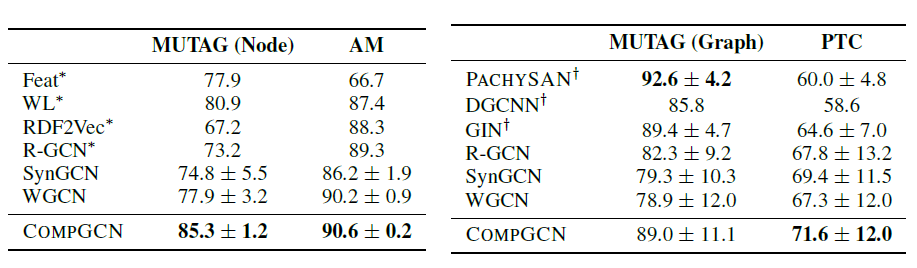
두 task 모두에서 baseline 모델들보다 월등히 뛰어난 정확도를 보여줍니다. 이를 통해 CompGCN 이 node embedding 만을 학습하는 기존의 GCN 보다 효과적으로 multi-relational graph 의 representation 을 학습함을 확인할 수 있습니다.
Future Study
여러가지 방면에서 CompGCN 에 대한 추가적인 연구가 이루어질 수 있습니다.
Composition operation \(\phi\) 를 non-parametrized operation 이 아닌, Neural Tensor Networks (NTN) 와ConvE 같은 parametrized operation 을 사용했을 때 CompGCN 의 성능이 개선될 것이라고 생각합니다.
RotatE 모델과 같이 relation 의 다양한 패턴들, symmetry / antisymmetry / inversion / composition, 을 반영할 수 있도록 score function 및 composition operation 에 대해 연구가 진행 될 수 있습니다.
CompGCN 에 대한 이론적인 연구가 필요합니다. 실험적으로 relation embedding 을 통해 multi-relational graph 의 representation 을 학습하는데 효과적이라는 것은 입증했지만, 어떤 이유로 효과적인에 대해 설명이 부족합니다. 특히 score function 과 composition operation 이 performance 에 미치는 영향에 대해 연구한다면, CompGCN 을 더 효과적으로 사용할 수 있을 것입니다.
Reference
Shikhar Vashishth, Soumya Sanyal, Vikram Nitin, and Partha P. Talukdar. Composition-based multi-relational graph convolutional networks. In ICLR, 2020.
Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv preprint arXiv:1902.10197, 2019.
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. Modeling relational data with graph convolutional networks. arXiv preprint arXiv:1703.06103, 2017.
Diego Marcheggiani and Ivan Titov. Encoding sentences with graph convolutional networks for semantic role labeling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 1506–1515. Association for Computational Linguistics, 2017
Leave a comment