
Continuous Graph Neural Networks
Updated:
[paper review] CGNN, ICML 2020
Introduction
GCN 의 propagation rule 은 neighbor node representation 들을 모아 각 node representation 을 update 합니다 [3]. 이 때 update 과정에서 각 node 와 주변의 node 들의 representation 이 점점 비슷해집니다. GCN layer 를 많이 쌓을수록 node 들의 representation 이 같은 값으로 수렴하는 over-smoothing 이 발생하기 쉽고, 이는 GCN 의 performance 를 저해하게 됩니다 [4]. 깊은 모델은 node feature 들의 복잡한 상호작용을 표현할 수 있기 때문에, over-smoothing 을 해결하는 것이 GNN 의 성능 향상에 있어 중요한 과제입니다.
논문에서는 node representation 의 시간에 따른 연속적인 변화를 표현할 수 있는 CGNN 모델을 제시합니다. CGNN 은 node representation 의 변화를 ODE 를 통해 표현하여 기존의 discrete GNN 을 연속적인 모델로 일반화시킵니다. ODE 에 restart distribution 을 추가하여 over-smoothing 문제를 해결하고, 그로 인해 node 들의 long-range dependency 를 학습할 수 있습니다. 특히 node classification 에 있어 기존의 GNN 모델들보다 성능이 뛰어나며, memory efficient 한 continuous-depth 모델입니다.
Preliminaries
Simple undirected graph \(G=(V,E)\) 의 adjacent matrix 를 \(Adj\) , degree matrix 를 \(D\) 라고 하겠습니다. 이 때 node 들의 degree 가 서로 다를 수 있기 때문에, normalized adjacent matrix \(D^{-1/2}Adj\,D^{-1/2}\) 를 주로 사용합니다. 하지만 normalized adjacent matrix 의 eigenvalue 는 \([-1,1]\) 구간에 존재하기 때문에, normalized adjacent matrix 로 정의된 convolution 을 사용할 경우 exploding / vanishing gradient 와 같은 instability 가 발생할 수 있습니다 [3].
따라서 [3] 에서는 renormalization trick 을 통해 normalized adjacent matrix 대신 \(\hat{A} = \tilde{D}^{-1/2}\tilde{A}\,\tilde{D}^{-1/2}\) 을 사용합니다. GCN 의 \(n\) 번째 layer 의 node representation \(H_n\) 과 weight matrix \(W\) 를 통해, propagation rule 을 다음과 같이 쓸 수 있습니다.
\[H_{n+1} = \hat{A}\,H_nW\]
논문에서는 normalized adjacent matrix 의 eigenvalue 의 크기를 조절하기 위해, renormalization trick 대신 parameter \(\alpha\in (0,1)\) 을 사용여 다음과 같은 regularized adjacency matrix \(A\) 를 사용합니다.
\[A = \frac{\alpha}{2}\left(I + D^{-1/2}Adj\,D^{-1/2} \right) \tag{1}\]이 때 정의에 의해 \(A\) 는 diagonalizable 하므로 \(A=U\Lambda U^T\) 로 표현한다면, \(A-I = U(\Lambda-I)U^T\) 입니다. 이 때 \(A\) 의 eigenvalue 는 \([0,\alpha]\) 구간에 존재하므로 \(\Lambda-I\) 의 diagonal element 들은 모두 0 보다 작고, \(A-I\) 는 invertible 합니다.
더 나아가 node 마다 regularization parameter \(\alpha\) 를 다르게 설정하기 위해, parmeter vector \(\tilde{\alpha}\in (0,1)^{\vert V\vert}\) 를 사용하여 새로운 regularized adjacency matrix \(\tilde{A}\) 를 정의할 수 있습니다.
\[\tilde{A} = \frac{1}{2}\,\text{diag}(\tilde{\alpha}) \left(I + D^{-1/2}Adj\,D^{-1/2} \right) \tag{2}\]\(A\) 와 마찬가지로 \(\tilde{A}\) 의 eigenvalue 는 \([0,1)\) 구간에 존재하며, \(\tilde{A}-I\) 또한 invertible 합니다. 논문의 실제 implementation 에서는 \((2)\) 의 regularized adjacency matrix 를 사용했습니다 [6].
Model
CGNN 은 크게 encoder, ODE solver, decoder 세 가지 부분으로 이루어져 있습니다. 먼저 encoder (fully connected layer) \(\mathcal{E}\) 는 각 node feature 를 latent space 로 보내주는 역할로, node feature matrix \(X\in\mathbb{R}^{\vert V\vert\times\vert F\vert}\) 를 \(E = \mathcal{E}(X)\) 로 변환해줍니다. 그 후 미리 준비된 ODE 와 initial value \(H(0):=E\) 에 대한 initial value problem 을 풀어주는 ODE solver 를 거쳐, 종료 시간 \(t_1\) 에 대한 node representation \(H(t_1)\) 을 만들어줍니다. 마지막으로 \(H(t_1)\) 은 decoder (fully connected layer) \(\mathcal{D}\) 를 거쳐 node-label matrix 로 변환됩니다. ODE solver 로는 최근 각광받는 Neural ODE [2] 를 사용합니다.
주어진 그래프에 대해 CGNN 의 architecture 는 그래프의 (normalized) adjacency matrix 와 종료 시간 \(t_1\), 그리고 node representation 의 변화를 표현하는 ODE 로 결정됩니다. CGNN 모델의 input 은 node feature matrix 이고, 이로부터 output 은 node-label matrix 가 됩니다. 다음의 그림을 통해 CGNN 의 구조를 이해할 수 있습니다. 그림에서 빨간색 화살표는 정보의 이동을 나타냅니다.
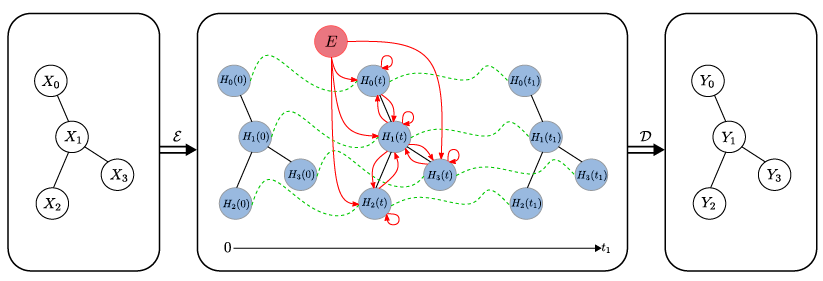
CGNN 에서 가장 중요한 것은 바로 node 들의 관계를 모델링해주는 ODE 입니다. ODE 는 node representation 의 연속적인 변화를 정의하며, node 들의 long-term dependency 를 표현할 수 있어야 합니다. 논문에서는 다음의 두 가지 ODE 를 제시합니다.
Case 1 : Independent Feature Channels
올바른 node representation 을 찾기 위해서는 node 들의 연결성을 반영해야 하기 때문에, ODE 는 그래프의 구조를 고려해야합니다. 논문에서는 PageRank 와 같은 diffusion-based method 로부터 영감을 받아, 다음의 propogation rule 을 정의합니다. 여기서 \(A\) 는 \((1)\) 의 정의를 따릅니다.
\[H_{n+1} = AH_n + H_0 \tag{3}\]
\((3)\) 의 node representation update 는 자신의 처음 representation \(H_0\) 를 기억하며, 주변 node representation 들의 정보를 모으는 과정으로 이해할 수 있습니다. 즉 원래의 node feature 를 잊어버리지 않으며 그래프의 구조를 학습할 수 있습니다. \((3)\) 를 통해 다음과 같이 \(H_n\) 을 직접 표현할 수 있습니다.
\[H_n = \left(\sum^n_{i=0} A^i\right)H_0 \tag{4}\]\((4)\) 를 통해 representation \(H_n\) 은 \(n\) 번째 layer 까지 propagated 된 정보 \(\left\{A^iH_0\right\}^{n}_{i=0}\) 를 모두 포함한다는 것을 알 수 있습니다.
이를 continuous 한 과정으로 일반화 시키기 위해, \((4)\) 를 Riemann sum 으로 바라봅니다. \(E=H_0\) 라 하고 partition \(\{ 0, 1, \cdots, n \}\) 과 \(\Delta t=1\) 에 대해, \((4)\) 를 Riemann sum 으로 표현하면 다음과 같습니다.
\[\sum^{n+1}_{i=1} A^{(i-1)\Delta t}E\Delta t \tag{5}\]
\((5)\) 에서 \(n\rightarrow\infty\) 이면, Riemann sum 으로부터 다음의 적분을 얻을 수 있습니다.
\[H(t) = \int^{t+1}_{0} A^sE\,ds \tag{6}\]\((6)\) 의 양변에 미분을 취하면,
\[\frac{dH(t)}{dt} = A^{t+1}E \tag{7}\]
이 때 \(t\) 가 정수가 아닌 경우 \(A^{t+1}\) 을 직접 계산할 수 없기 때문에, 한 번 더 미분을 취해줍니다.
\[\frac{d^2H(t)}{dt^2} = \ln A\,A^{t+1}E = \ln A\frac{dH(t)}{dt} \tag{8}\]
이후 \((8)\) 의 양변을 다시 적분해줌으로써 다음의 ODE 를 얻습니다.
\[\frac{dH(t)}{dt} = \ln A\,H(t) + const \tag{9}\]\((6)\) 으로부터 \(t=0\) 일 때, \(H(0)\) 의 값을 구할 수 있습니다.
\[\ln A\,H(0) = \int^1_0 \ln A\,A^sE\,ds = \left( A-I\right)E \tag{10}\]
\((7)\) 과 \((10)\) 으로부터 \((9)\) 의 적분상수 \(const\) 를 계산할 수 있습니다.
\[\begin{align} AE = \left.\frac{dH(t)}{dt}\right|_{t=0} &= \ln A\,H(0) + const \\ &= (A-I)E + const \end{align}\]
따라서 다음의 Proposition 1 을 얻을 수 있습니다.
Proposition 1.
The discrete dynamic in \((3)\) is a discretisation of the following ODE :
\[\frac{dH(t)}{dt} = \ln A\,H(t)+E \tag{11}\]with the initial value \(H(0)=\left(\ln A\right)^{-1}\left( A-I\right)E\)
\((11)\) 의 \(\ln A\) 는 직접 계산할 수 없으므로, 1차 항까지의 Taylor expansion 을 통해 \(\ln A\approx A-I\) 로 근사해줍니다.
\[\frac{dH(t)}{dt} = (A-I)H(t) + E \tag{12}\]
\((12)\) 의 ODE 는 epidemic model 의 관점에서 이해할 수 있습니다. 또한 \((12)\) 의 양변에 integrating factor \(e^{-(A-I)t}\) 를 곱해주면, 다음의 ODE 로부터 Proposition 2 를 보일 수 있습니다.
\[\frac{d}{dt}\,e^{-(A-I)t}\,H(t) = e^{-(A-I)t}E\]Proposition 2.
The analytical solution of the ODE defined in \((12)\) is given by :
\[H(t) = (A-I)^{-1}\left( e^{(A-I)t}-I \right)E + e^{(A-I)t}E \tag{13}\]
Preliminaries 에서 설명했듯이 \(A-I\) 의 eigenvalue 는 \([-1,\alpha-1]\subset [-1,0)\) 구간에 존재합니다. 즉 \(t\rightarrow\infty\) 이라면, \((13)\) 의 matrix exponential \(e^{(A-I)t}\) 는 0 으로 수렴합니다. 따라서, 충분히 큰 \(t\) 에 대해 \(H(t)\) 를 다음과 같이 근사할 수 있습니다.
\[H(t)\approx (I-A)^{-1}E = \left( \sum^{\infty}_{i=0}A^i \right)E \tag{14}\]
\((3)\) 과 형태를 비교하면, \((14)\) 의 \(H(t)\) 는 모든 layer 에서 전파된 정보 \(\left\{A^iE\right\}^{\infty}_{i=0}\) 들을 포함한다는 것을 볼 수 있습니다. 즉 discrete 한 layer 의 representation 정보를 모두 반영하기 때문에, node 들의 long-term dependency 를 잘 표현할 수 있습니다.
\((1)\) 의 정의에 의해, \(\alpha\) 가 \(A\) 의 eigenvalue 의 크기를 정해줍니다. \(\alpha\) 가 작아질수록 \(A^i\) 이 \(\mathbf{0}\) 으로 더 빠르게 수렴하기 때문에, \(\alpha\) 를 통해 \((14)\) 의 representation \(H(t)\) 가 반영하는 neighborhood 의 크기를 조절할 수 있습니다. 이런 특성을 활용하기 위해 CGNN 은 모델의 학습 과정에서 parameter \(\alpha\) 를 같이 학습합니다.
더 나아가 각 node 마다 \(\alpha\) 를 다르게 설정하기 위해, \((1)\) 에서 정의된 \(A\) 대신 \((2)\) 에서 정의한 \(\tilde{A}\) 를 사용합니다. \(\tilde{A}\) 를 사용해도 \((12)\) 와 \((14)\) 의 결과가 동일하게 성립하기 때문에, 실제 implementation 에서는 \((2)\) 를 사용하여 parameter vector \(\tilde{\alpha}\) 를 학습합니다.
Case 2 : Modelling the Interaction of Feature Channels
\((3)\) 으로부터 파생된 ODE \((12)\) 는 각 feature channel 들이 독립적이며 서로 영향을 주지 않습니다. 하지만 feature channel 들 사이의 영향을 무시할 수 없기 때문에, 이를 모델링할 수 있는 ODE 를 만들어야 합니다. \((3)\) 에서 각 channel 들의 상호작용을 표현하기 위해, weigh matrix \(W\in\mathbb{R}^{d\times d}\) 를 사용하여 다음의 discrete 한 propagation rule 을 생각합니다.
\[H_{n+1} = AH_nW + H_0 \tag{15}\]
Case 1 과 동일하게 \((15)\) 를 Riemann sum 으로 바라보아, Proposition 3 를 얻을 수 있습니다.
Proposition 3.
Suppose that the eigenvalue decompositions of \(A\), \(W\) are \(A=P\Lambda P^{-1}\) and \(W=Q\Phi Q^{-1}\), respectively, then the discrete dynamic in \((15)\) is a discretisation of the following ODE :
\[\frac{dH(t)}{dt} = \ln A\,H(t)+ H(t)\ln\,W +E \tag{16}\]with the initial value \(H(0)=PFQ^{-1}\), where
\[F_{ij} = \frac{\Lambda_{ii}\tilde{E}_{ij}\Phi_{jj} - \tilde{E}_{ij}}{\ln\,\Lambda_{ii}\Phi_{jj}} \tag{17}\]where \(\tilde{E} = P^{-1}EQ\).
마찬가지로 \(\ln A\) 와 \(\ln W\) 를 직접 계산할 수 없기 때문에, \((16)\) 에서 \(\ln A\approx A-I\) 와 \(\ln W\approx W-I\) 로 근사하여, 다음의 ODE 를 얻을 수 있습니다. 이 때 초기값은 \(H_0\) 로 동일합니다.
\[\frac{dH(t)}{dt} =(A-I)H(t)+ H(t)(W-I) +E \tag{18}\]\((18)\) 의 ODE 는 Sylvester differential equation 으로 알려져있으며, Proposition 4 의 analytical solution 을 가지고 있습니다.
Proposition 4.
Suppose the eigenvalue decompositions of \(A-I\) and \(W-I\) are \(A-I=P\Lambda'P^{-1}\) and \(W-I=Q\Phi'Q^{-1}\), respectively, then the analytical solution of the ODE in \((18)\) is given by :
\[H(t) = e^{(A-I)t}Ee^{(W-I)t} + PF(t)Q^{-1} \tag{19}\]where \(F(t)\in\mathbb{R}^{\vert V\vert\times d}\) with each element defined as follows :
\[F_{ij}(t) = \frac{\tilde{E}_{ij}}{\Lambda'_{ii}+\Phi'_{jj}}e^{(\Lambda'_{ii}+\Phi'_{jj})t} - \frac{\tilde{E}_{ij}}{\Lambda'_{ii}+\Phi'_{jj}}\]where \(\tilde{E}=P^{-1}EQ\).
만약 Proposition 4 에서 \(W\) 의 eigenvalue 가 1 이하라고 가정한다면, \(A-I\) 의 eigenvalue 는 \((-1,0)\) 에 존재하며 \(W-I\) 의 eigenvalue 는 \((-1,0]\) 에 존재하기 때문에, 다음과 같이 matrix exponential 들이 \(\mathbf{0}\) 으로 수렴합니다.
\[\lim_{t\rightarrow\infty} e^{(A-I)t}\rightarrow 0 \;,\;\;\; \lim_{t\rightarrow\infty} e^{(\Lambda'_{ii}+\Phi'_{jj})t}\rightarrow 0\]
따라서, 충분히 큰 \(\;t\) 에 대해 \(H(t)\) 를 다음과 같이 근사할 수 있습니다.
\[\left(P^{-1}H(t)Q\right)_{ij} \approx -\frac{\tilde{E}}{\Lambda'_{ii}+\Phi'_{jj}} \tag{20}\]\((20)\) 에서 \(W=I\) 를 대입하면, \((14)\) 의 결과와 같다는 것을 확인할 수 있습니다. 즉 \((11)\) 의 ODE 는 \((16)\) 의 ODE 의 특수한 케이스입니다.
실제 implementation 에서는 \(W\) 가 diagonalizable 하도록, 학습 가능한 orthogonal matrix \(U\) 와 학습 가능한 vector \(M\) 을 사용해 \(W\) 를 다음과 같이 표현합니다.
\[W=U\,\text{diag}(M)U^T\]학습 과정에서 \(M\) 의 clipping 을 통해 \(W\) 의 eigenvalue 가 1 이하이도록 만들어주며, \(U\) 가 orthogonal matrix 가 되도록 hyperparameter \(\beta\) 를 사용해 트레이닝 스텝마다 다음과 같이 U 를 update 해줍니다.
\[U \leftarrow (1+\beta)U-\beta(UU^T)U\]논문에서는 \(\beta=0.5\) 로 고정합니다. 또한 Case 1 과 마찬가지로 \(A\) 대신 \(\tilde{A}\) 를 사용하여 parameter vector \(\tilde{\alpha}\) 를 학습합니다. 마지막으로 학습의 안정화를 위해 \(H(t)\) 에 auxiliary dimension 을 추가하는 방법을 활용하지만, performance 에는 큰 차이가 없습니다.
Discussion
기존의 discrete 한 layer 를 사용하는 GCN 과 비교하여, CGNN 은 다음과 같은 이점이 있습니다.
Robustness with time to over-smoothing
기존의 discrete 한 layer 를 사용하는 GCN 은 node classification, graph classification, link prediction 등 다양한 영역에서 좋은 성능을 보여주지만, layer 의 개수에 따라 성능에 큰 차이를 보입니다. GCN layer 수가 적다면 expressive 한 representation 을 학습할 수 없고, 반대로 layer 의 수가 많다면 over-smoothing 으로 인해 제대로된 representation 을 학습할 수 없습니다. 특히 [5] 에서 GCN layer 의 수가 많아질수록 기하급수적으로 node representation 에 정보 손실이 발생함을 보였습니다. 그에 비해 CGNN 은 성능이 \(t_1\) 에 크게 영향을 받지 않음을 실험적으로 알 수 있고, \((14)\) 에서 확인할 수 있듯이 \(t\rightarrow\infty\) 이어도 representation 에 정보 손실은 없습니다.
Global dependencies
GCN layer 의 수가 적다면 node representation 에 가까운 주변 node 들의 정보만을 반영할 수 있습니다. 즉 expressive 한 모델을 만들기 위해서는, 더 깊은 모델을 통해 멀리 떨어진 node 들의 정보들을 반영할 수 있어야합니다. \((14)\) 에서 볼 수 있듯이 시간 \(t\) 가 충분히 크다면 representation \(H(t)\) 가 \(\left\{A^i E\right\}^{\infty}_{i=0}\) 들의 합으로 표현되기 때문에, CGNN 은 node 들의 long-term dependency 를 학습할 수 있습니다.
Diffusion constant
\((1)\) 에서 정의된 \(A\) 는 parameter \(\alpha\) 를 통해 \(A^{i}\) 이 0 으로 수렴하는 속도를 조절할 수 있습니다. 특히 \(A\) 대신 \(\tilde{A}\) 를 사용하면, 각 node 마다 diffusion constat \(\alpha\) 를 다르게 줄 수 있기 때문에 expressive 한 representation 학습에 큰 도움이 됩니다.
Entangling channels during graph propagation
Case 2 의 \((18)\) ODE 를 사용하면 서로 다른 feature channel 들의 상호작용을 표현할 수 있습니다. 특히 \((19)\) 를 통해, 상호작용을 나타내는 weight matrix \(W\) 의 eigenvalue 들이 node representation 에 어떤 영향을 끼치는지 설명할 수 있습니다.
Insight into the role of the restart distribution
\((12)\) 와 \((18)\) 의 ODE 에서 node representation \(H(t)\) 의 시간에 따른 미분값은 restart distribuion \(H(0)=E\) 에 의존합니다. \((12)\) 의 ODE 에서 \(E\) 가 더해지지 않은 다음의 ODE 를 보겠습니다.
\[\frac{dH(t)}{dt} = (A-I)H(t) \tag{21}\]\((21)\) 의 analytical solution 은 \(H(t)=e^{(A-I)t}\,H(0)\approx A^tH(0)\) 입니다. \(t\rightarrow\infty\) 에 따라 최종 representation 이 으로 \(\mathbf{0}\) 수렴하기 때문에 학습하고자 하는 representation 과 부합합니다. 또한 실험을 통해 \((21)\) 의 ODE 를 사용한 CGNN (CGNN discrete) 은 종료 시간 \(t_1\) 이 증가함에 따라 성능이 감소하는 것을 확인할 수 있습니다.
Experiment
Semi-supervised node classification task 에 대한 CGNN 모델의 performance 를 측정하기 위해, [3] 에서 사용한 dataset 을 그대로 사용했습니다. Dataset 은 네 가지의 citation network Cora, Citeseer, Pubmed, NELL 이며, 실험 방법 또한 [3] 의 방법을 따랐습니다.
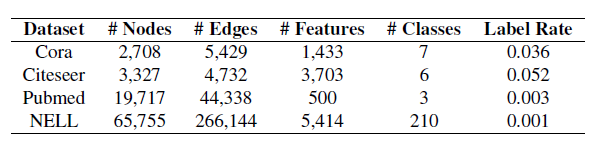
실험의 baseline 모델로는 discrete 한 GNN 모델인 GCN, GAT 와 continuous 한 GNN 모델 GODE 를 선택했습니다. GODE 는 node representation 의 연속적인 변화를 GNN 으로 매개화한 ODE 를 통해 표현하며, ODE 를 매개화하는 GNN 으로 GCN (GCN-GODE) 과 GAT (GAT-GODE) 를 골랐습니다. CGNN 의 variant 들로는 Case 1 의 CGNN, Case 2 의 weight matrix 를 사용한 CGNN with weight, 그리고 \((3)\) 의 discrete propagation rule 을 사용한 CGNN discrete 모델을 선택했습니다.
Performance comparison
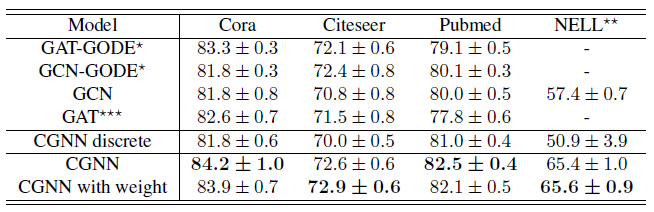
각 dataset 에 대해, basline 모델들과 CGNN 모델들의 정확도는 다음의 표에 정리되어있습니다.
또한 각 dataset 들에서 15 개의 random split 에 대한 모델들의 정확도는 다음의 표를 통해 확인할 수 있습니다.
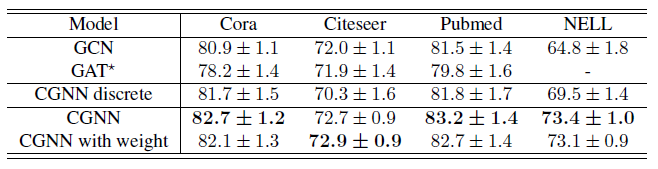
GCN 과 GAT 와 비교해 CGNN (CGNN with weight) 의 정확도가 훨씬 놓은 것을 볼 수 있습니다. 이는 CGNN 이 node 들의 long-term dependency 를 학습할 수 있기 때문입니다. 또한 GODE 와 비교했을 때 Cora 와 Pubmed 에서 훨씬 높은 성능을 보입니다. CGNN 은 그래프에서 node 들의 long-term dependency 를 반영할 수 있도록 잘 설계된 ODE 를 사용하는 반면, GODE 는 기존의 GCN 혹은 GAT 와 같은 GNN 으로 매개화된 ODE 를 사용하기 때문에 node representation 의 변화에 대한 학습의 차이가 생깁니다.
CGNN variant 들을 비교해보면, CGNN discrete 보다 CGNN (CGNN with weight) 의 성능이 더 뛰어납니다. 즉 node representation 의 변화를 continuous 하게 모델링하는 것이 효과적임을 알 수 있습니다. CGNN 과 CGNN with weight 의 성능 차이는 미미한데, 아마도 사용한 dataset 이 복잡하지 않기 때문이라고 생각됩니다. 더 복잡한 knowledge graph 혹은 protein-protein interactions network 와 같은 dataset 에서는 performance 의 차이가 뚜렷하게 나타날 것이라고 봅니다.
Performance with respect to time steps
CGNN 의 이점 중 하나는 바로 over-smoothing 이 일어나지 않는다는 것입니다. 이를 확인하기 위해 GCN 과 GAT 에서는 layer 의 수에 따른 정확도를, CGNN 에서는 종료 시간 \(t_1\) 에 따른 정확도를 비교했습니다. 결과는 다음의 그래프에 나타나 있습니다.
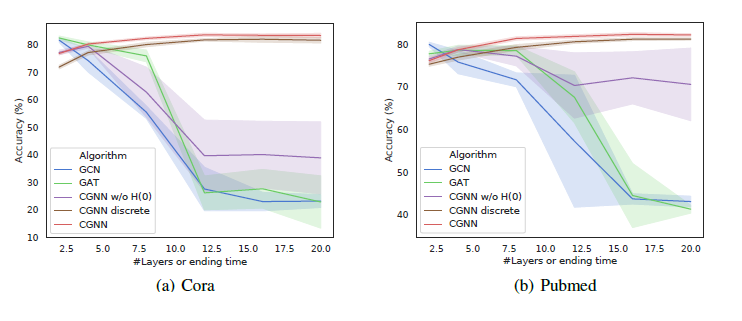
GCN 과 GAT 와 같은 모델은 layer 의 수가 2 혹은 3일 때 가장 높은 정확도를 보이며, layer 의 수가 많아질수록 정확도가 감소하는 것을 볼 수 있습니다. 그에 비해 CGNN 은 종료 시간이 증가함에 따라 정확도도 올라가며, 결국 수렴하는 경향을 관찰할 수 있습니다. 즉 CGNN 은 over-smoothing 이 일어나지 않고, node 들의 long-term dependency 를 학습할 수 있다는 것을 실험적으로 확인했습니다.
또한 restart distribution \(H(0)=E\) 를 사용하지 않은 모델 CGNN w/o H(0) 는 GCN, GAT 와 같이 layer 의 수가 커질수록 정확도가 떨어지는 것을 볼 수 있습니다. 이를 통해 restart distribution 이 over-smoothing 을 해결하는 중요한 역할을 한다는 것을 알 수 있습니다.
Memory Efficiency
마지막으로 CGNN 모델의 종료 시간 \(t_1\) 에 따른 memory 사용량을 확인했습니다.
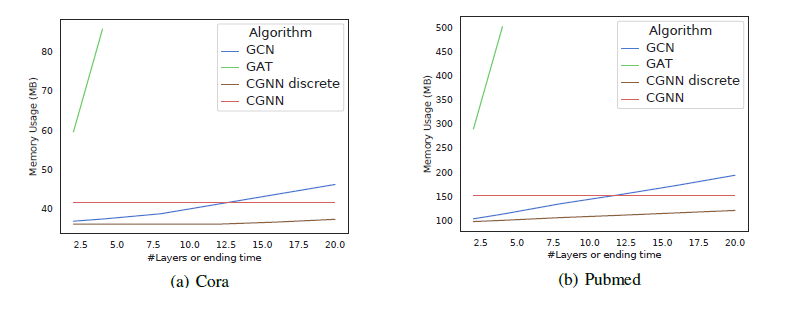
node representation 의 변화를 discrete 하게 표현하는 모델들 : GCN, GAT, CGNN discrete 은 layer 의 수에 따라 memory 사용량이 linear 하게 증가했습니다. 그에 비해 adjoint sensitivity method [2] 를 사용하는 CGNN 은 memory 사용량이 일정하게 적은 것을 볼 수 있습니다. 따라서 CNN 은 memory efficient 하기 때문에, large graph 에 대해서도 적용할 수 있습니다.
Future Work
CGNN 은 homophily, 즉 node 가 주변의 이웃한 node 들과 비슷한 feature 를 가진다고 가정합니다. 이를 확장해, homophily 뿐만 아니라 structural equivalence 를 반영할 수 있도록 \((3)\) 과 \((15)\) 의 discrete propagation rule 을 정의하는 방향으로의 연구가 기대됩니다. 특히, diffusion-based 에서 더 나아가 domain-specific ODE 를 사용한다면 분자 구조, 단백질의 결합, knowledge graph 과 같이 node 들 사이의 더 복잡한 관계를 가지는 상황에서도 우수한 성능을 보여줄 수 있다고 생각합니다.
Reference
L.-P. A. Xhonneux, M. Qu, and J. Tang. Continuous graph neural networks. arXiv preprint arXiv:1912.00967, 2019.
Tian Qi Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31, pages 6571–6583. Curran Associates, Inc., 2018.
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semisupervised learning. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
Kenta Oono and Taiji Suzuki. Graph neural networks exponentially lose expressive power for node classification. In International Conference on Learning Representations, 2020.
Continuous Graph Neural Networks Github : https://github.com/DeepGraphLearning/ContinuousGNN
Leave a comment