
Graph Attention Networks
Updated:
[paper review] : GAT, ICLR 2018
Introduction
CNN 은 image classification, semantic segmentation, machine translation 등 다양한 분야에 적용되어 좋은 성능을 보여주었습니다. CNN 의 핵심인 convolution 은 주어진 data 의 구조가 grid-like (Euclidean domain) 특성을 가질 때 정의됩니다. 3D mesh, social network, biological network 등과 같이 irregular 한 그래프 data 에 대해 convolution operator 를 일반화시키기 위한 다양한 연구가 이루어지고 있습니다.
Graph domain 에서 convolution 을 일반화시키는 연구는 크게 두 가지로 나눌 수 있습니다. 첫번째 방법은 spectral approach 로, graph Laplacian 을 통해 Fourier domain 에서 convolution 을 정의합니다. 이 때 eigendecomposition 과 같은 복잡한 행렬 연산과 non-spatially localized filter 의 문제를 해결하기 위해, ChebNet 은 Chebyshev expansion 을 사용했고, 더 나아가 [2] 에서는 Chebyshev expansion 을 각 node 의 1-step neighborhood 에 한정시켜 node classification, link prediction, graph classification 등 다양한 분야에서 좋은 성능을 보여주는 GCN 을 제시했습니다. 하지만 spectral approach 의 가장 큰 문제점은 바로 그래프의 전체 구조에 의존한다는 것입니다. Input graph 에 따라 graph Laplacian 이 변하기 때문에, inductive learning 에 직접 적용될 수 없습니다.
두번째 방법은, non-spectral approach 입니다. 공간적으로 가까운 neighbor 를 통해 그래프에서 직접 convolution 을 정의합니다. Graph Laplacian 을 사용하지 않기 때문에 spectral approach 의 문제점을 피해가지만, 크기가 다른 neighborhood 들에 대해서 적용되며 CNN 의 weight-sharing 특성을 유지하는 convolution operator 를 정의하는 것은 굉장히 어렵습니다. 대표적인 모델로 MoNet 과 GraphSAGE [3] 가 있습니다.
논문은 [4] 에서 제시된 attention mechanism 을 통해 non-spectral appoach 의 문제점을 해결합니다. Attention mechanism 의 장점은, 고정되지 않은 input size 에 적용될 수 있다는 점입니다. 그래프에서 크기가 다른 neighborhood 들에 대해서도 공통적으로 적용될 수 있기 때문에, attention mechansim 을 통한 non-spectral approach 는 weight-sharing 특성을 가질 수 있습니다.
GAT Architecture
Graph Attentional Layer
들어가기 앞서, \(N\) 개의 node 를 가지는 그래프에 대해 node \(i\) 의 feature 를 vector \(h_i\in\mathbb{R}^{F}\) 로 나타내겠습니다. 여기서 \(F\) 는 node 의 input feature dimension 이며, \(F'\) 을 output 의 feature dimension 이라고 하겠습니다. 또한, node 의 ordering 에는 의미가 없으며 단순히 node 를 구분하기 위한 notation 입니다.
GAT 를 이루는 graph attentional layer 는, 모든 node 들에 대해 공통된 weight matrix \(W\in\mathbb{R}^{F'\times F}\) 와 self-attention \(\mathcal{A}:\mathbb{R}^{F'}\times\mathbb{R}^{F'}\rightarrow\mathbb{R}\) 로 이루어집니다. 먼저 self-attention 을 통해 attention coefficient \(e_{ij}\) 를 다음과 같이 계산합니다.
\[e_{ij} = \mathcal{A}\left( Wh_i, Wh_j \right) \tag{1}\]\((1)\) 의 attention coefficient \(e_{ij}\) 는 node \(i\) 에 대한 node \(j\) 의 중요도 (importance) 로 해석할 수 있습니다. 만약 모든 node 들의 쌍에 대해 attention coefficient 를 사용한다면, 그래프의 구조적인 특성을 무시하게 됩니다. GAT 의 핵심은, 바로 node \(i\) 의 neighborhood \(N_i\) 에 속하는 node \(j\) 들에 대해서만 coefficient \(e_{ij}\) 를 사용하는 것입니다. Masked attention 을 통해 그래프의 구조에 대한 정보를 살릴 수 있습니다.
각 node 들에 대해 \((1)\) 의 coefficient 들을 비교할 수 있도록, [4] 에서와 같이 softmax 함수를 통해 정규화를 해줍니다.
\[\alpha_{ij} = \text{softmax}_j(e_{ij}) = \frac{\exp(e_{ij})}{\sum_{k\in N_i}\exp(e_{ik})} \tag{2}\]논문에서는 \(\mathcal{A}\) 를 weight vector \(a\in\mathbb{R}^{2F'}\) 와 LeakyReLU 를 사용해 다음과 같이 정의합니다.
\[\mathcal{A}\left( Wh_i, Wh_j \right) = \text{LeakyReLU}\left( a^T\left[ Wh_i\vert\vert Wh_j \right] \right) \tag{3}\]아래의 그림은 \((3)\) 의 과정을 나타냅니다.
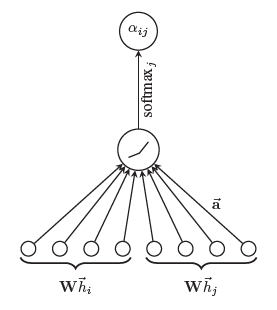
\((3)\) 을 적용해 \((2)\) 를 다시 표현하면 다음과 같이 쓸 수 있습니다.
\[\alpha_{ij} = \frac{\exp\left( \text{LeakyReLU}\left( a^T\left[ Wh_i\,\Vert\, Wh_j \right] \right) \right)}{\sum_{k\in N_i}\exp\left(\text{LeakyReLU}\left( a^T\left[ Wh_i\,\Vert\, Wh_k \right] \right)\right)} \tag{4}\]\((4)\) 의 정규화된 attention coefficient 를 통해 다음과 같이 node \(i\) 의 feature vector 를 update 해줍니다.
\[h_i \leftarrow \sigma\left( \sum_{j\in N_i}\alpha_{ij}Wh_j \right) \tag{5}\]
또한 논문에서는 self-attention 의 학습 과정을 안정화시키기 위해, transformer 에 대한 논문 “Attention is all you need” 의 방법과 같이 multi-head attention 을 사용했습니다. \(K\) 개의 independent 한 attention mechanism \((5)\) 들의 concatenation 을 통해 다음과 같이 새로운 layer-wise propagation rule 을 정의합니다.
\[h_i \leftarrow \Big\Vert^{K}_{k=1} \sigma\left( \sum_{j\in N_i}\alpha^{k}_{ij}W^kh_j \right) \tag{6}\]\(K=3\) 일 때 independent 한 attention mechanism 들을 서로 다른 색의 화살표로 표현한다면, \((6)\) 의 식을 아래의 그림과 같이 이해할 수 있습니다.
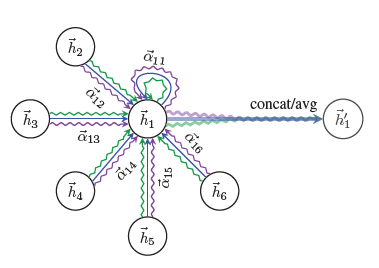
마지막 layer 에서는 concatenation 대신 feature 들의 averaging 을 통해 final output 을 만들어줍니다.
\[h_i \leftarrow \sigma\left( \frac{1}{K}\sum^K_{k=1}\sum_{j\in N_i}\alpha^{k}_{ij}W^kh_j \right) \tag{7}\]
GAT 의 가장 큰 장점은 계산이 효율적으로 이루어질 수 있다는 것입니다. Self-attentional layer 는 모든 edge 들에 대해 병렬화가 가능하고, node 의 output feature 는 각 node 마다 병렬적으로 계산이 가능합니다. 특히 spectral approach 에서와 같은 eigendecomposition 혹은 복잡한 행렬 연산이 필요하지 않습니다. 1개의 head 에 대한 \((6)\) 의 계산 복잡도는 \(O\left(\vert V\vert FF' + \vert E\vert F'\right)\) 이며, 이는 GCN 의 복잡도와 비슷합니다.
GAT vs GCN
GCN 과의 가장 큰 차이는 동일한 neighborhood 내의 node 들에 대해 다른 importance 를 부여할 수 있다는 점입니다. GCN 의 layer-wise propagation rule 은 normalization constant \(c_{ij}=\sqrt{\vert N_i\vert\vert N_j\vert}\) 를 통해 다음과 같이 나타낼 수 있습니다.
\[h_i \leftarrow \sigma\left( \sum_{j\in N_i}\frac{1}{c_{ij}}Wh_j \right) \tag{8}\]\((5)\) 와 비교해보면, \(c_{ij}\) 는 값이 고정되어 있지만 \(\alpha_{ij}\) 는 weight vector \(a\in\mathbb{R}^{2F'}\) 에 따라 변할 수 있습니다. Weight 가 고정되어 있지 않기 때문에 GCN 보다 더 expressive 하고다는 것을 알 수 있습니다.
또한 \((8)\) 에서 볼 수 있듯이 GCN 은 학습 전에 그래프의 전체 구조에 대한 정보 (graph Laplacian) 를 알고 있어야합니다. GAT 의 경우 전체 구조에 대한 정보가 필요 없기 때문에 GCN 과 다르게 inductive learning 에 직접 이용될 수 있습니다.
GAT vs GraphSAGE
GraphSAGE 는 대표적인 non-spectral approach 로, GAT 와 비슷한 propagation rule 을 따릅니다. 하지만 GraphSAGE 는 GAT 와의 달리 neighborhood 중 일부만을 sample 해 사용합니다. 이는 계산량을 한정시키기 위해 선택한 방법으로, 추론 과정에서 neighborhood 중 일부의 정보만을 이용하게 됩니다. 또한 LSTM 을 aggregator 로 사용한 GraphSAGE 와 다르게, GAT 는 node 의 ordering 과 무관합니다.
Evaluation
Datasets
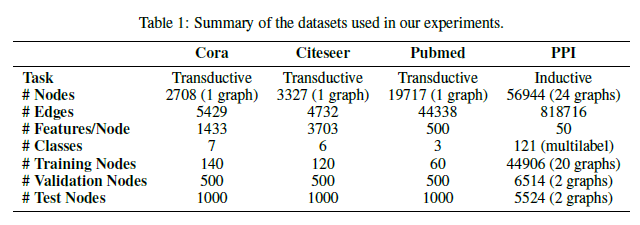
GAT 모델을 다른 baseline 모델들과 비교하기 위해, 잘 알려진 4 가지 dataset 에서 실험을 진행했습니다. Transductive learning 의 performance 측정을 위해 Cora, Citeseer, Pubmed 세 가지의 citation network dataset 을 사용했습니다. 또한 inductive learing 의 performance 측정을 위해 protein-protein interaction (PPI) dataset 에서도 실험을 수행했습니다. 각 dataset 의 특징은 아래의 table 1 에 정리되어 있습니다.
Transductive Learning
Transductive learning task 의 baseline 들로는 [2] 의 실험에서 사용된 baseline 들과 함께 GCN 을 사용했습니다. GAT 와 baseline 모델들의 성능은 mean classification error 로 측정되었고, 결과는 아래의 표에 정리되어 있습니다.
![]()
GCN 과의 비교를 통해, 같은 neighborhood 내의 node 들에 대해 다른 weight 를 부여하는 방법이 효과적임을 알 수 있습니다.
Inductive Learning
Transductive learning task 의 baseline 들로 활용된 모델들은 inductive learning 에 직접적으로 적용되기 힘들기 때문에, inductive learning task 의 baseline 에서 제외했습니다. Inductive learning task 의 baseline 들로는 GraphSAGE 의 variant 들을 선택했습니다. 특히 GraphSAGE 모델 중 성능이 좋다고 알려진 두 모델 : pool aggregator 를 사용하는 GraphSAGE-pool 과 LSTM aggregator 를 사용하는 GraphSAGE-LSTM 과 더불어 aggregator 로 GCN 또는 mean 을 사용한 GraphSAGE-GCN, GraphSAGE-mean 총 네 개의 모델을 골랐습니다.
GAT 모델이 그래프 구조에 대한 정보를 이용하는지 확인하기 위해, 그래프의 구조를 전혀 이용하지 않는 multilayer perceptron (MLP) classifier 를 실험에 포함시켰습니다. 또한 GAT 모델의 특징 중 한 가지가 바로 같은 neighborhood 내의 node 들에 대해서 다른 weight 를 부여할 수 있다는 것인데, 이를 확인하기 위해 constant attention mechanism 을 사용한 Const-GAT 모델을 GAT 모델과 함께 비교했습니다.
GAT 와 baseline 모델들의 성능은 micro-averaged \(F_1\) score 로 측정되었으며, 결과는 아래의 표에 정리되어 있습니다.
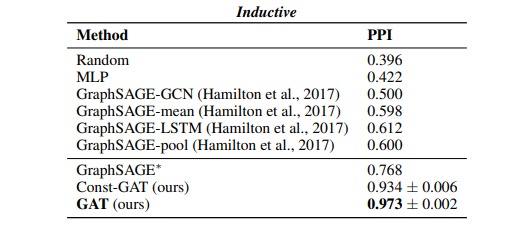
GraphSAGE 의 performance 와 비교를 통해, neighborhood 의 일부만 sampling 하는 것보다 전체 neighborhood 를 이용하는 것이 효과적임을 확인할 수 있습니다. 또한 Const-GAT 모델과의 비교를 통해 다시 한번 같은 neighborhood 내의 node 들에 대해서 다른 weight 를 부여하는 것이 중요하다는 것을 알 수 있습니다.
논문에서는 GAT 모델을 통해 학습한 feature representation 을 눈으로 확인하기 위해, data visualization 을 위해 많이 사용되는 t-SNE (stochastic neighbor embedding) 를 아래의 그림과 같이 시각화 했습니다.
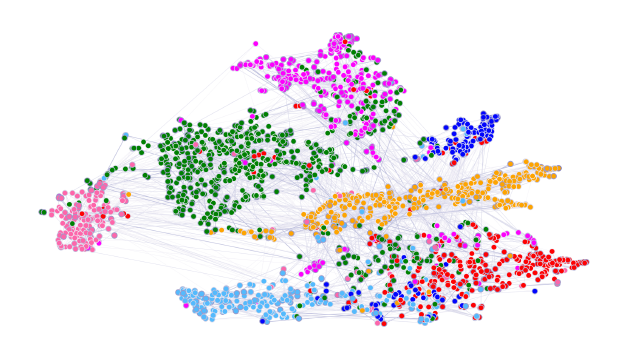
Node 의 색은 7개의 class 에 해당하며, 각각의 class 끼리 clustering 된 것을 볼 수 있습니다.
Conclusion
GAT 는 graph-structured data 에 적용될 수 있는 convolutin-style 의 neural network 로 다음과 같은 특징을 가지고 있습니다.
Computationally Efficient
앞서 설명했듯이, 계산이 효율적으로 이루어질 수 있습니다. Self-attentional layer 는 모든 edge 들에 대해 병렬화가 가능하고, node 의 output feature 는 각 node 마다 병렬적으로 계산이 가능합니다. 특히 복잡한 행렬 연산을 사용하지 않습니다.
Different Importance
같은 neighborhood 내의 node 들에 대해 다른 weight 을 부여해줄 수 있습니다. 이웃한 node 들에 대해 weight 이 고정되어 있지 않기 때문에, GCN 보다 expressive 한 특성을 가집니다.
Inductive Learning
Node 들이 서로 다른 degree 를 가지는 그래프에도 적용할 수 있으며, 그래프의 전체 구조에 의존하지 않기 때문에 inductive learning 이 가능합니다.
GAT 는 attention mechanism 을 사용하기 때문에, 학습된 attentional weight 를 통해 모델의 해석에 도움을 줄 수 있습니다. Attentional weight 을 이용한 model interpretability 관련 연구가 기대됩니다.
Reference
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. arXiv preprint arXiv:1710.10903, 2017.
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, pages 1024–1034, 2017.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. International Conference on Learning Representations (ICLR), 2015.
Leave a comment