
Semi-Supervised Classification with Graph Convolutional Networks
Updated:
[paper review] : GCN, ICLR 2017
Introduction
논문에서 해결하고자 하는 문제는 다음과 같습니다.
Classifying nodes in a graph where labels are only available for a small subset of nodes.
즉 그래프의 node 들 중 label 이 주어진 node 들의 수가 적은 상황에서 출발합니다.
Graph Convolution Network 를 사용하기 이전에는, 주로 explicit graph-based regularization (Zhu et al., 2003) 을 이용하여 문제에 접근하였습니다. 이 방법은 supervised loss \(\mathcal{L}_0\) 에 graph Laplacian regularization 항 \(\mathcal{L}_{reg}\) 을 더한 loss function 을 학습에 사용합니다. Neural network 와 같이 differentiable 함수 \(f\) 와 feature vector matrix \(X\), 그리고 unnormalized graph Laplacian \(L\) 로 Laplacian regularization 을 다음과 같이 정의합니다.
\[\mathcal{L} = \mathcal{L}_0 + \lambda\mathcal{L}_{reg},\;\;\; \mathcal{L}_{reg} = f(X)^T\,L\,f(X) \tag{1}\]\(\mathcal{L}_{reg}\) 를 자세히 들여다보면, 그래프의 adjacency matrix \(A\) 에 대해 다음을 만족합니다.
\[f(X)^T\;L\;f(X) = \sum_{i,j} A_{ij} \|f(X_i)-f(X_j)\|^2\]\(\mathcal{L}_{reg}\) 의 값이 작다는 것은 곧 인접한 두 node 의 feature 가 비슷하다는 뜻입니다. 이와 같이 explicit graph-based regularization 은 그래프의 인접한 node 들은 비슷한 feature 를 가질 것이라는 가정을 전제로 하기 때문에, 일반적인 상황에서 제약을 받습니다.
논문에서는 Explicit graph-based regularization 을 사용하지 않기 위해 그래프의 구조를 포함하는 neural network model \(f(X,A)\) 를 제시합니다. [1] 에서 제시된 spectral convolution 과 [3] 의 truncated Chebyshev expansion 을 사용한 ChebyNet 을 발전시킨 Graph Convolutional Network (GCN) 을 통해 semi-supervised node classification 을 해결합니다.
Fast Approximate Convolutions On Graphs
Spectral Graph Convolution
Graph signal \(x\in\mathbb{R}^N\) 와 filter \(g_{\theta}=\text{diag}(\theta)\) 에 대해 spectral convolution 은 다음과 같이 정의됩니다 [1, 2].
\[g_{\theta}\ast x = Ug_{\theta}U^Tx \tag{2}\]여기서 \(U\) 는 normalized graph Laplacian \(L = I - D^{-1/2}AD^{-1/2}\) 의 eigenvector 로 이루어진 Fourier basis 이고, \(L=U\Lambda U^T\) 로 표현할 수 있습니다.
Filter \(g_{\theta}\) 는 다음과 같이 \(L\) 의 eigenvalue 들의 함수로 생각할 수 있습니다 [3].
\[g_{\theta}(\Lambda) = \begin{bmatrix} g_{\theta}(\lambda_0) & & & \\ & g_{\theta}(\lambda_1) & & \\ & & \ddots & \\ & & & g_{\theta}(\lambda_{N-1}) \end{bmatrix}\]\((2)\) 을 계산하기 위해서는 \(U\) 의 matrix multiplication 을 수행해야하며, 이는 \(O(N^2)\) 으로 상당히 복잡한 연산입니다. 또한 \(U\) 를 구하기 위한 eigendecomposition 은 복잡도가 \(O(N^3)\) 이므로, node 의 개수가 수천 수만개인 그래프에 대해서 \((2)\) 를 계산하는 것은 굉장히 힘듭니다.
이를 해결하기 위해, truncated Chebyshev expansion 을 통해 \(g_{\theta}(\Lambda)\) 를 다음과 같이 근사합니다 [3, 5].
\[g_{\theta'}(\Lambda) \approx \sum^K_{k=0} \theta'_{k}T_k(\tilde{\Lambda}) \tag{3}\]여기서 \(\tilde{\Lambda} = \frac{2}{\lambda_{max}}\Lambda - I\) 로 정의하고, \(L\) 의 가장 큰 eigenvalue \(\lambda_{max}\) 를 사용해 Chebyshev expansion 을 위해 \(\Lambda\) 를 scaling 해준 것입니다.
\((3)\) 의 근사를 \((2)\) 에 대입하면, \(\tilde{L} = \frac{2}{\lambda_{max}}L - I\) 에 대해 다음의 결과를 얻을 수 있습니다.
\[g_{\theta'}\ast x \approx \sum^K_{k=0} \theta'_kT_k(\tilde{L})x = y \tag{4}\]\((4)\) 의 결과가 특별한 이유는 각 node 에 대해 localized 되어 있기 때문입니다. 우선 graph Laplacian \(L\) 은 다음과 같이 localization 특성을 가집니다 [5].
\(\left(L^s\right)_{ij}\) 는 그래프의 두 node \(i\) 와 \(j\) 를 연결하는 path 들 중 길이가 \(s\) 이하인 path 들의 개수와 일치한다.
\((4)\) 에서 \(L\) 의 \(K\)-th power 까지만 존재하기 때문에, \(y(i)\) 는 \(i\) 의 \(K\)-th order neighborhood signal 들의 합으로 표현할 수 있습니다. 따라서 \((4)\) 의 근사는 \(K\)-localized 됨을 확인할 수 있습니다.
Layer-wise Linear Model
\((4)\) 에서 \(K\) 가 클수록 더 많은 종류의 convolutional filter 를 얻을 수 있지만, 그만큼 계산이 복잡해지며 overfitting 의 가능성도 커집니다. 여러개의 convolutional layer 를 쌓아 deep model 을 만든다면, \(K\) 가 작아도 다양한 종류의 convolutional filter 를 표현할 수 있습니다. 특히 overfitting 의 가능성을 덜 수 있고, 한정된 자원에 대해서 $K$ 가 클 때보다 더 깊은 모델을 만들 수 있습니다.
이 논문에서는 극단적으로 \(K=1\) 로 제한을 두었습니다. 또한 normalized graph Laplacian 의 eigenvalue 들은 \([0,2]\) 구간에 속하기 때문에 [6], \(\lambda_{max}\approx 2\) 로 근사합니다.이 경우 \((4)\) 는 다음과 같이 두 개의 parameter \(\theta'_0\) 와 \(\theta'_1\) 을 통해 표현할 수 있습니다.
\[g_{\theta'}\ast x \approx \theta'_0x + \theta'_1(L-I)x = \theta'_0x - \theta'_1D^{-1/2}AD^{-1/2}x\]더 나아가, 계산을 줄이기 위해 하나의 parameter \(\theta = \theta'_0 = -\theta'_1\) 만을 사용한다면, 다음과 같은 간단한 결과를 얻게됩니다.
\[g_{\theta}\ast x \approx \theta(I + D^{-1/2}AD^{-1/2})x \tag{5}\]\(M = I + D^{-1/2}AD^{-1/2}\) 의 eigenvalue 는 \([0,2]\) 에 속합니다 [Appendix A]. 그렇기 때문에, \((5)\) 를 사용한 layer 를 여러개 쌓아 deep model 을 만든다면 exploding / vanishing gradient problem 과 같이 불안정한 학습이 이루어질 수 있습니다.
논문에서는 이를 해결하기 위해 renormalization trick 을 사용합니다. \(\tilde{A} = A + I\) 와 \(\tilde{D}_{ii} = \sum_j \tilde{A}_{ij}\) 에 대해, \((5)\) 에서 \(I + D^{-1/2}AD^{-1/2}\) 대신 \(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\) 를 이용해 다음과 같이 convolutional filter 를 정의합니다 [Appendix B].
\[g_{\theta}\ast x \approx \theta\, \tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2} x \tag{6}\]\((6)\) 의 결과는 각 node 가 1차원의 feature 를 가질 때로 한정되어 있습니다. 이제 각 node 마다 \(C\) 차원의 feature vector 를 가지는 상황을 고려하겠습니다. 주어진 signal \(X\in\mathbb{R}^{N\times C}\) 와 \(F\) 개의 feature map 에 대해서 \((6)\) 을 다음과 같이 일반화할 수 있습니다 [Appendix C].
\[Z = \tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}X\Theta \tag{7}\]여기서 \(\Theta\in\mathbb{R}^{C\times F}\) 는 filter의 parameter matrix 이고 \(Z\in\mathbb{R}^{N\times F}\) 가 filtering 의 결과입니다. 특히 \(\Theta\) 는 그래프의 모든 node 들에 대해 동일하게 사용되기 때문에, CNN 의 filter 와 같이 weight-sharing 의 관점에서 큰 의미가 있습니다.
\((7)\) 을 사용해 muli-layer GCN 의 layer-wise propagation rule 을 정의할 수 있습니다. \(l\) 번째 layer 와 \(l+1\) 번째 layer 의 activation 을 다음과 같이 쓰면,
\[H^{(l)}\in\mathbb{R}^{N\times C_l}\, , \;\; H^{(l+1)}\in\mathbb{R}^{N\times C_{l+1}}\]trainable weight matrix \(W^{(l)}\in\mathbb{R}^{C_l\times C_{l+1}}\) 와 activation function \(\sigma\) (e.g. ReLU, tanh) 를 사용해 다음과 같이 propagation rule 을 정의할 수 있습니다.
\[H^{(l+1)} = \sigma\left( \tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\,H^{(l)}W^{(l)} \right) \tag{8}\]\((8)\) 에서 혼동하지 말아야 점은, 각 layer 들에 대해 그래프의 구조 (node 들과 node 들의 연결 상태) 는 변하지 않고, 각 node 에 주어진 feature vector 의 dimension \(C_l\) 만 변한다는 것입니다.
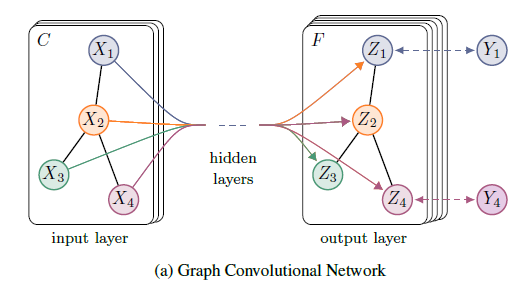
Semi-Supervised Node Classification
Example : Two-layer GCN
\((8)\) 의 propagation rule 을 사용해 node classification 을 위한 two-layer GCN 을 보겠습니다.. 먼저 전처리 단계에서 \(\hat{A} = \tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\) 를 계산하여 다음과 같이 두 개의 layer 를 가지는 model 을 만들 수 있습니다.
\[Z = \text{softmax}\left( \hat{A}\;\text{ReLU}\left( \hat{A}XW^{(0)} \right)W^{(1)} \right) \tag{9}\]마지막 output layer 에서 activation function 으로 softmax 를 각 행 별로 적용해줍니다. Loss function 으로 label 이 있는 node 들에 대해서만 cross-entropy error 를 계산합니다.
\[\mathcal{L} = -\sum_{l\in\text{labled}}\sum^{\text{output dim}}_{f=1} Y_{lf}\ln Z_{lf}\]이를 통해 \((9)\) 의 weight matrix \(W^{(0)}\) 와 \(W^{(1)}\) 은 gradient descent 를 통해 업데이트 합니다.
Experiments & Results
실험 방법 및 데이터에 관해서 더 자세한 설명은 Yang et al., 2016 을 참고하기 바랍니다.
Datasets
논문에서는 크게 네 가지 dataset : Citeseer, Cora, Pubmed, NELL 을 실험에 사용했습니다.
이들 중 Citeseer, Cora, 그리고 Pubmed 는 citation network dataset 으로, 각 node 는 문서들이며 edge 는 citation link 를 의미합니다. NELL 은 knowledge graph 에서 추출된 이분 그래프 dataset 으로 relation node 와 entity node 모두 사용했습니다.
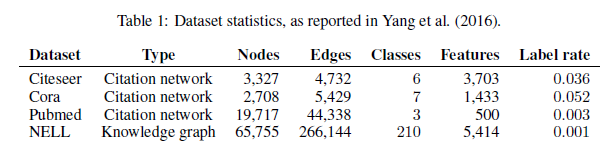
Node Classification
각 데이터셋에 대한 baseline method 들과 two-layer GCN 의 classification accuracy 는 다음과 같습니다.
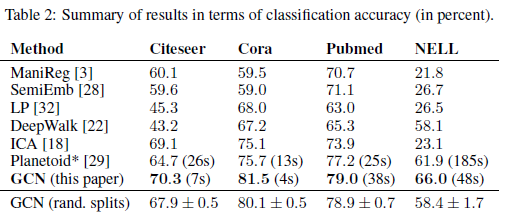
GCN 의 정확도가 다른 baseline method 들에 비해 월등히 높은 것을 볼 수 있습니다. 특히 baseline method 들 중 정확도가 가장 높은 Planetoid 와 비교해, GCN 의 수렴 속도가 훨씬 빠르다는 것을 알 수 있습니다.
Evaluation of Propagation Model
위에서 제시된 다양한 propagation model 들의 performance 를 비교한 결과는 다음과 같습니다.

\((7)\) 에서 사용한 renormalization trick 이 가장 높은 정확도를 보여줍니다.
Appendix
A. Largesest Eigenvalue of \(M\)
\(M = I + D^{-1/2}AD^{-1/2}\) 가 real symmetric matrix 이기 때문에, Courant-Fischer 정리에 의해 \(M\) 의 가장 큰 eigenvalue \(\mu\) 는 다음을 만족합니다.
\[\mu = \sup_{\|x\|=1} x^TMx\]\(L\) 의 정의에 의해 \(M = 2I-L\) 이며 \(L\) 은 positive semi-definite matrix 이기 때문에, \(\|x\|=1\) 를 만족하는 \(x\in\mathbb{R}^N\) 에 대해 다음이 성립합니다.
\[x^TMx =x^T(2I-L)x = 2 - x^TLx \leq 2\]따라서,
\[\mu = \sup_{\|x\|=1} x^TMx \leq 2\]B. About Renormalization Trick
\(I + D^{-1/2}AD^{-1/2}\) 와 \(\tilde{D}^{-1/2}\tilde{A}\,\tilde{D}^{-1/2}\) 의 matrix 를 자세히 살펴보면 다음과 같습니다.
\[I + D^{-1/2}AD^{-1/2} = \begin{cases} 1 & i=j \\ A_{ij}/\sqrt{D_{ii}D_{jj}} & i\neq j \end{cases}\] \[\tilde{D}^{-1/2}\tilde{A}\,\tilde{D}^{-1/2} = \begin{cases} 1/(D_{ii}+1) & i=j \\ A_{ij}/\sqrt{(D_{ii}+1)(D_{jj}+1)} & i\neq j \end{cases}\]C. Generalization to high dimensional feature vectors
먼저 filter 의 개수가 1개일 때를 생각하겠습니다. 각 node 가 \(C\) 차원의 feature vector 를 가질 때, 이를 signal \(X\in\mathbb{R}^{N\times C}\) 로 표현할 수 있습니다.
\[X = \begin{bmatrix} \vert & & \vert \\ x_1 & \cdots & x_C \\ \vert & & \vert \end{bmatrix}\]\(X\) 의 각 column 은 특정 feature 에 대한 signal \(x_{i}\in\mathbb{R}^N\) 입니다. 각 feature 마다 convolutional filter \((6)\) 을 적용해 새로운 feature \(Z\in\mathbb{R}^N\) 를 얻어내는 과정을 다음과 같이 표현할 수 있습니다.
\[\begin{align} Z &= \sum^{C}_{i=1} \hat{A}x_i\theta_i\\ &= \begin{bmatrix} \vert & & \vert \\ \hat{A}x_1 & \cdots & \hat{A}x_C \\ \vert & & \vert \end{bmatrix} \begin{bmatrix} \theta_1 \\ \vdots \\ \theta_C \end{bmatrix} \\ \\ &= \hat{A}\; \begin{bmatrix} \vert & & \vert \\ x_1 & \cdots &x_C \\ \vert & & \vert \end{bmatrix} \begin{bmatrix} \theta_1 \\ \vdots \\ \theta_C \end{bmatrix} = \hat{A}X\Theta \end{align}\]이제 Filter 의 개수가 \(F\) 개라면, \(i\) 번째 filter 로 만들어진 새로운 feature \(Z_i = \hat{A}X\Theta_i\) 들에 대해 다음과 같이 정리할 수 있습니다.
\[\begin{align} Z &= \begin{bmatrix} \vert & & \vert \\ Z_1 & \cdots & Z_F \\ \vert & & \vert \end{bmatrix} = \begin{bmatrix} \vert & & \vert \\ \hat{A}X\Theta_1 & \cdots & \hat{A}X\Theta_F \\ \vert & & \vert \end{bmatrix} \\ \\ &= \hat{A}X\begin{bmatrix} \vert & & \vert \\ \Theta_1 & \cdots &\Theta_F \\ \vert & & \vert \end{bmatrix} = \hat{A}X\Theta \end{align}\]
Reference
Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral networks and locally connected networks on graphs. In International Conference on Learning Representations (ICLR), 2014.
M. Henaff, J. Bruna, and Y. LeCun. Deep Convolutional Networks on Graph-Structured Data. arXiv:1506.05163, 2015.
Michael Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in neural information processing systems (NIPS), 2016.
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR), 2017.
David K Hammond, Pierre Vandergheynst, and Remi Gribonval. Wavelets on graphs via spectral graph theory. Applied and Computational Harmonic Analysis, 30(2):129–150, 2011.
F. R. K. Chung. Spectral Graph Theory, volume 92. American Mathematical Society, 1997.
Leave a comment